Construindo um Agente de Trading LLM por $1.30/Dia na Hyperliquid
Arquitetura e análise de custos de um agente autônomo de trading com LLM em futuros perpétuos de crypto. O que construímos, o que funciona, e o que ainda não validamos.
A Arquitetura
A maioria dos projetos de “bot de trading com LLM” custa centenas de dólares por dia porque despeja dados brutos de mercado no GPT-4. Isso é desperdício. LLMs são ruins em matemática mas bons em raciocinar sobre contexto.
Nossa arquitetura: Python calcula todas as features quantitativas. O LLM interpreta. Python executa.
┌─────────────────┐ ┌──────────────┐ ┌────────────────┐
│ Data Layer │────▶│ LLM Analysis │────▶│ Execution │
│ (Python) │ │ (Claude) │ │ (Python) │
│ │ │ │ │ │
│ • On-chain data │ │ • Interprets │ │ • Risk limits │
│ • Funding rates │ │ context │ │ • Position │
│ • OI snapshots │ │ • Structured │ │ sizing │
│ • Panic scores │ │ decision │ │ • Order mgmt │
│ • Book depth │ │ │ │ │
│ Cost: $0 │ │ Cost: ~$1.20 │ │ Cost: $0 │
└─────────────────┘ └──────────────┘ └────────────────┘O Que Está Construído e Rodando
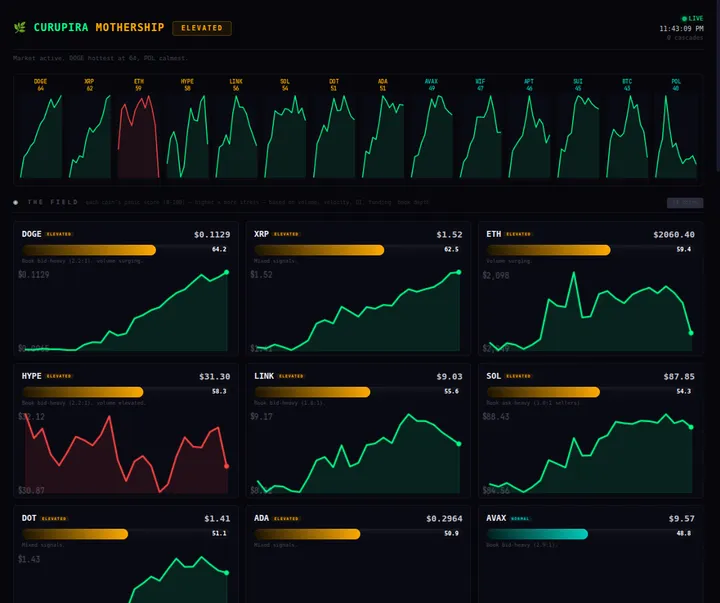
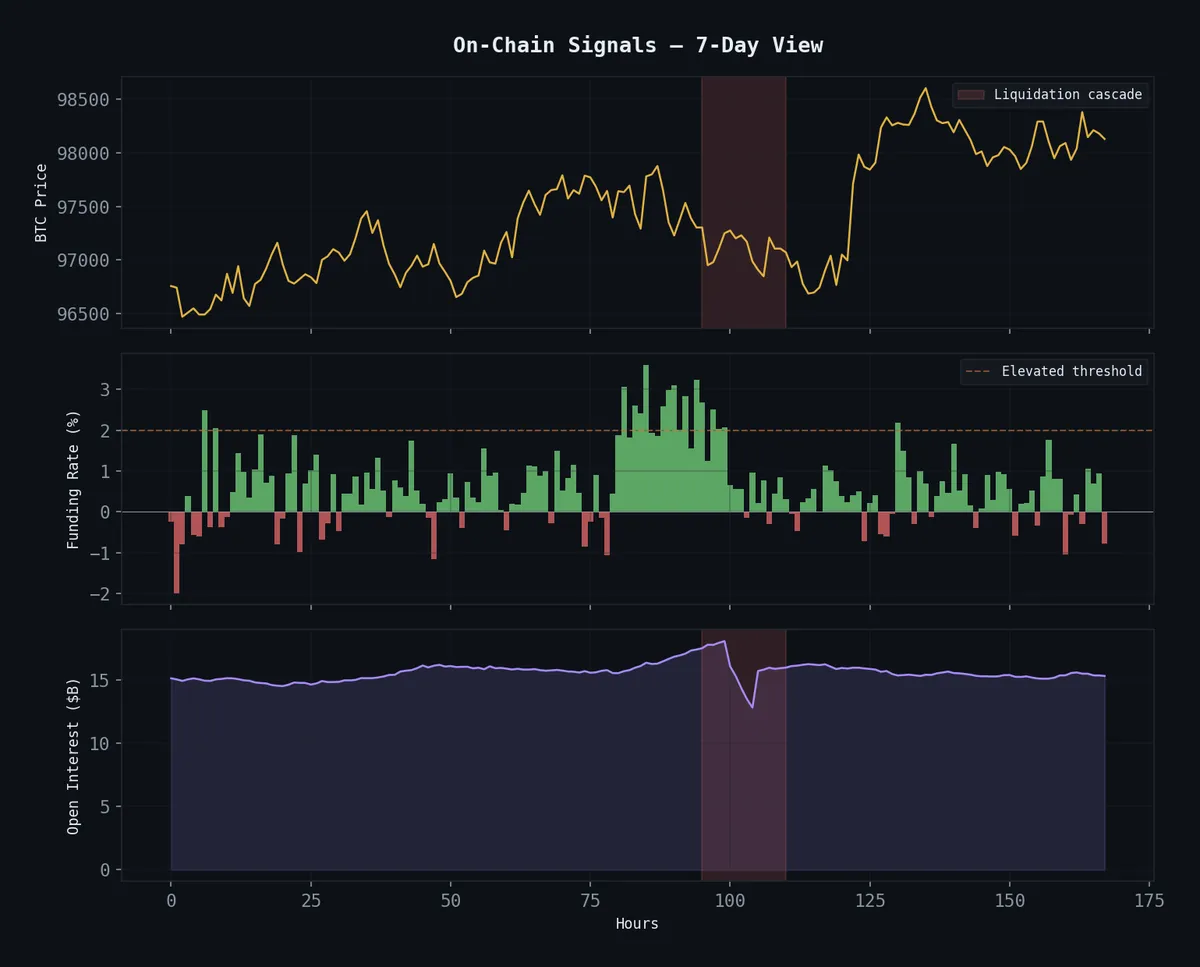
Coletor on-chain (onchain-collector.timer): Roda a cada 30 minutos via systemd. Puxa snapshots de 6 moedas da Hyperliquid — funding rates, open interest, mark price, volume 24h, oracle price, ordens abertas. Armazena em SQLite + JSONL.
Monitor de liquidações (liq-watcher.service): Conexão WebSocket persistente com a Hyperliquid. Monitora 14 moedas em tempo real. Calcula um panic score por moeda baseado em:
- Z-score de volume (relativo ao baseline de 1 hora)
- Velocidade do preço
- Variações de OI
- Extremos de funding rate (calibrados a partir de perfis de distribuição de 90 dias)
- Desequilíbrio do book de ofertas
Quando o pânico cruza o threshold → alerta de cascata com call direcional.
Banco de dados de mercado: SQLite com 4 tabelas — funding_history (30K+ registros), snapshots, trade_events, distribution_profiles. Distribuições de funding por moeda computadas a partir de 90 dias de dados preenchidos retroativamente.
O que NÃO está rodando: A camada de decisão LLM. O agente ainda não opera. Estamos calibrando a infraestrutura de sinais primeiro — não faz sentido conectar o Claude a um sistema que produz falsos positivos.
O Panic Scorer
O problema de calibração foi instrutivo. Primeira versão: panic scores de 0-100, tudo travado em 100 em mercados calmos porque o baseline de volume estava errado. Segunda versão: centrado em 50, thresholds de funding por moeda a partir de perfis de distribuição no percentil 95/5, amortecimento de cold-start de 15 minutos.
# Per-coin funding thresholds (from distribution profiles)
# BTC: extreme_long=0.000013, extreme_short=-0.000025
# SOL: extreme_long=0.000013, extreme_short=-0.000059
# POL: extreme_long=0.000013, extreme_short=-0.000107Esses números vêm do perfilamento real das distribuições de funding. A maioria das moedas tem thresholds de extreme_long quase idênticos (~0.000013), mas thresholds de extreme_short absurdamente diferentes — o extremo short de POL é 4× o de BTC. Usar um único threshold fixo para todas as moedas estava errado.
Projeção de Custos
| Componente | Frequência | Custo Diário Estimado |
|---|---|---|
| Snapshots on-chain | A cada 30 min | $0 (API Hyperliquid gratuita) |
| Monitor de liquidações | WebSocket contínuo | $0 |
| Análise LLM | A cada 15 min (projetado) | ~$1.20 (Sonnet) |
| VPS | 24/7 | ~$0.10 |
| Total | ~$1.30 |
A infraestrutura de dados roda de graça. O custo é inteiramente das chamadas LLM, que ainda não estamos fazendo.
Por Que Hyperliquid
- Zero taxas de gas em trades
- Transparência on-chain — cada trade verificável
- Liquidez profunda em BTC/ETH ($50M+ de book depth)
- API REST + WebSocket simples
- Mercados 24/7 — sem lógica de abertura/fechamento
- Futuros perpétuos com até 50× de alavancagem
O Que Está Bloqueado
- Chave API da Anthropic — rodamos Claude via assinatura, não créditos de API. Precisamos de uma chave API separada para o agente.
- Carteira testnet Hyperliquid — precisa configurar testnet antes de tocar em dinheiro real.
- Calibração de sinais — o panic scorer acabou de ser reconstruído com thresholds baseados em distribuição. Precisa de ~1 semana de dados para validar que a nova calibração não produz falsos positivos.
O plano: forward-test em testnet primeiro, coletar snapshots de replay para análise offline, depois gradualmente conectar o Claude para interpretação assim que a infraestrutura de sinais estiver estável.
Perguntas Honestas que Não Respondemos
- O raciocínio do LLM realmente adiciona alpha sobre execução baseada em regras? Achamos que sim — síntese contextual, consciência de regime, confiança auto-calibrada. Mas não fizemos teste A/B.
- $1.30/dia é sustentável? Se a Anthropic aumentar preços ou precisarmos do Opus para decisões complexas, os custos podem facilmente multiplicar por 5-10×.
- Os alertas de cascata serão operáveis? Os dois primeiros alertas foram falsos positivos de artefatos de cold-start. Precisamos de semanas de dados limpos para saber a qualidade do sinal.
Publicaremos resultados quando tivermos. Não antes.
Para as estratégias quantitativas que o agente usará, veja ECVT. Para a metodologia de sinais on-chain, veja Dados On-Chain. Visão geral da arquitetura em Agentes Autônomos.