De PyTorch a 27 Megabytes: Um Filtro Neural de Trades num VPS Barato
Treinamos uma rede neural para filtrar trades ao vivo, deployamos num VPS de $9, descobrimos que nosso provedor de dados estava alucinando barras de fim de semana — e depois removemos a NN inteira porque 302 trades nunca foram suficientes para generalizar. A engenharia de deploy foi real. O edge não.
Atualização (Março 2026): O filtro NN foi removido do trading ao vivo em ~25 de fevereiro de 2026. Estava fazendo overfitting em 302 trades. A estratégia IPDA CE crua sem o filtro se mostrou mais pura. Epílogo completo abaixo.
O Problema Com Win Rates
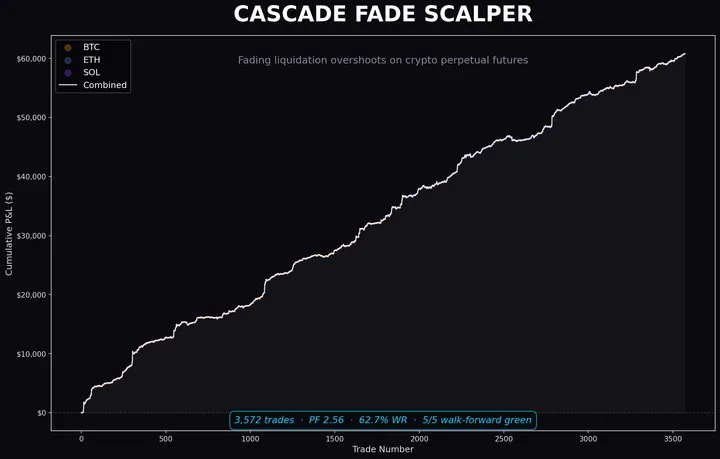
Nossa estratégia EURUSD de 30 minutos sobreviveu a cinco rodadas de deflação honesta. O piso: 302 trades, 59.6% win rate, +463 pips, profit factor 1.48 em 2.5 anos.
40% dos trades perdem. Alguns setups cheiram errado antes da entrada — chop de segunda de manhã, ruído no meio da sessão, sinais obsoletos. A pergunta: uma rede neural consegue aprender quais trades pular?
A resposta acabou sendo não. Mas a jornada nos ensinou coisas que valem a pena guardar.
Os Padrões Condicionais
Antes de treinar qualquer coisa, rodamos análises post-hoc no baseline de 302 trades:

Segunda sozinha carrega 80% do lucro total (PF 3.56, 73.9% WR). Terça e quinta são negativos líquidos. Isso se manteve ao longo de 2.5 anos.

O padrão se repete intraday: 09:00 UTC (abertura de Londres) e 13:00 UTC (abertura de NY) são vencedores. Horários no meio da sessão perdem. O edge se concentra nas transições de sessão.
Esses padrões condicionais são reais. O problema não eram os padrões — era tentar ensinar uma rede neural a capturá-los com 302 amostras. Um humano poderia simplesmente operar segundas-feiras e aberturas de sessão com regras fixas. Mas nós queríamos fronteiras suaves, filtros probabilísticos. Essa ambição precisava de ordens de magnitude mais dados do que tínhamos.
O Que a Rede Vê
Onze features. Sem dados de preço — a estratégia já tomou sua decisão estrutural. A NN vê apenas metadados:
features = [
is_london_open, # sessão (binário)
is_long, # direção (binário)
hour_sin, hour_cos, # codificação cíclica da hora
dow_sin, dow_cos, # codificação cíclica do dia da semana
signal_age_normalized, # idade do setup (0-20 dias)
signal_size_normalized, # tamanho do setup em pips
risk_pips_normalized, # distância do SL
is_monday, # flag de segunda-feira
is_session_open, # flag de hora de abertura de sessão
]Codificação cíclica importa. Hora 23 e hora 0 são vizinhas, não estão a 23 de distância. Sem isso, a rede acha que sexta-feira está maximamente distante de segunda.
Arquitetura: Deliberadamente Simples
Input (11) → Linear(32) → ReLU → Linear(16) → ReLU → Linear(1) → SigmoidTrês camadas. 593 parâmetros. Deliberadamente pequena porque 302 trades é um dataset minúsculo. Uma rede mais profunda memorizaria.
Ela memorizou mesmo assim.
Treinamento: ensemble de 10 modelos com seeds aleatórias diferentes, state dicts com média. BCEWithLogitsLoss, Adam, 300 epochs, batch 32. O ensemble deveria suavizar ruído dependente de seed. Com tão poucas amostras, ele suavizou ruído num sabor diferente de ruído.
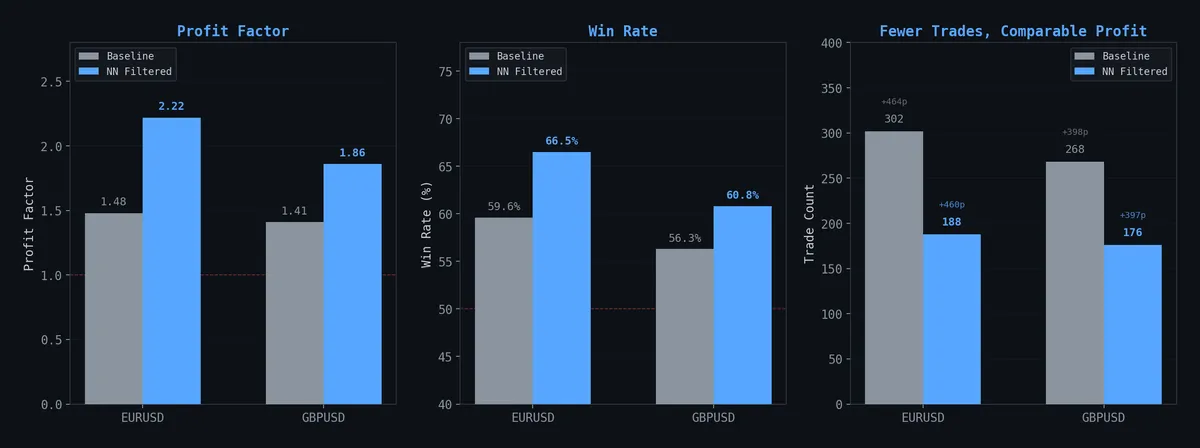
O Efeito do Filtro (In-Sample)

EURUSD no limiar P(win) ≥ 0.45:
| Métrica | Baseline | NN Filtrado | Mudança |
|---|---|---|---|
| Trades | 302 | 188 | -38% |
| Win Rate | 59.6% | 66.5% | +6.9pp |
| Profit Factor | 1.48 | 2.22 | +50% |
| Pips Totais | +463 | +460 | -0.6% |
Mesmo lucro, 38% menos trades, PF dramaticamente melhor. No papel, a rede removeu ruído sem sacrificar edge.
A curva de equity ficou mais limpa:

A curva filtrada (azul) acompanha o mesmo ponto final que o baseline (cinza) mas com menos drawdown e menos períodos flat. Bonito. Suspeito.
Como os Scores se Separam

Os scores P(win) não estavam perfeitamente separados — 58.6% de acurácia OOS. As distribuições mudaram ligeiramente: vitórias agruparam mais alto, perdas mais baixo. O limiar de 0.45 cortou a cauda esquerda onde perdas dominam.
58.6% de acurácia OOS numa tarefa de classificação binária com 302 amostras. Isso deveria ter sido o sinal de alerta. Isso mal está acima do acaso, e “mal acima do acaso” numa amostra pequena é indistinguível de ruído.
Escolhendo o Limiar

Escolhemos 0.45 porque ficava no joelho: PF estabilizou em ~2.2 enquanto pips totais ainda acompanhavam o baseline. Acima de 0.50, o filtro matava vencedores reais também. Abaixo de 0.40, trades marginais demais sobreviviam.
Ajuste de limiar num dataset de 302 amostras é ajustar uma curva a estática.
Cross-Pair: Não Transfere
Testamos o modelo EURUSD no GBPUSD. Acurácia de transferência: 44%. Pior que jogar uma moeda. Padrões temporais são específicos por par.
Um modelo GBPUSD independente mostrou o mesmo padrão in-sample — PF saltando de 1.41 para 1.86 enquanto preservava pips. Mesma miragem de 302 amostras, par diferente.
EURGBP baseline PF era 1.08. Morto na chegada.
Validação Estatística (Que Não Validou o Que Achávamos)
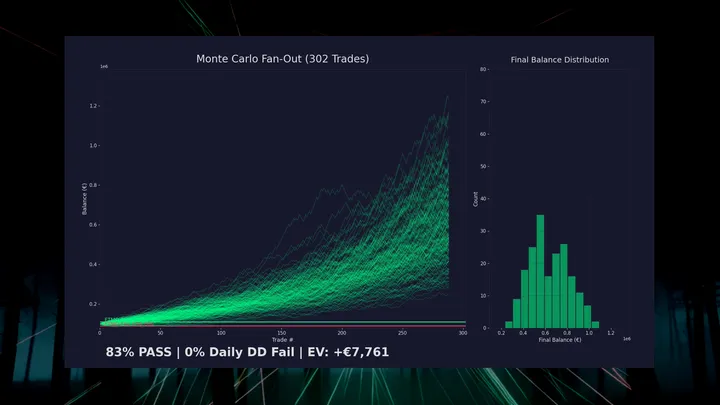
Bootstrap Monte Carlo — 200 caminhos de equity simulados:

Mesmo o resultado do percentil 5 produz +188 pips. O detalhamento mensal:

21 de 32 meses lucrativos. Pior: -38 pips. Melhor: +129 pips.

Drawdown máximo: -101 pips (~12% de drawdown na conta com 1% de risco).
Essas estatísticas validaram a estratégia baseline, não o filtro NN. O edge bruto do IPDA CE é real. O Monte Carlo prova que a distribuição subjacente de trades se sustenta. A contribuição da NN? Não validada em nenhum período out-of-sample que importa.
O Problema do VPS
Trading ao vivo roda num VPS Windows Contabo de $9/mês — 2 vCPUs, 4GB RAM, MT5, Task Scheduler a cada 30 minutos.
PyTorch CPU-only: ~2GB instalado. Num VPS de 4GB rodando MT5 e Windows, isso não é viável. O modelo tem 593 parâmetros. Três multiplicações de matrizes e dois ReLUs. Precisamos de multiplicação, não diferenciação automática.
A Reescrita em Numpy
Esse trabalho de engenharia continua genuinamente útil independente do valor preditivo da NN.

# Exportar uma vez (requer torch, rodar localmente):
def export_weights(pt_path, json_path):
checkpoint = torch.load(pt_path, map_location="cpu")
sd = checkpoint["model_state_dict"]
weights = {
"W1": sd["net.0.weight"].tolist(),
"b1": sd["net.0.bias"].tolist(),
# ... mesmo para camadas 2, 3
}
Path(json_path).write_text(json.dumps({"weights": weights, ...}))
# Inferência (apenas numpy, roda no VPS):
class TradeScorer:
def _forward(self, x: np.ndarray) -> np.ndarray:
h1 = np.maximum(0, x @ self._W1.T + self._b1) # ReLU
h2 = np.maximum(0, h1 @ self._W2.T + self._b2) # ReLU
return (h2 @ self._W3.T + self._b3).squeeze(-1) # logitArquivos de pesos: 21KB JSON. Memória em runtime: 3.7KB. Inferência: ~0.1ms por trade. O VPS saiu de “não dá pra instalar torch” para “não precisa de torch.” Se você precisar deployar um modelo PyTorch pequeno num ambiente com recursos limitados, esse padrão funciona. Exporte os pesos como JSON, reconstrua o forward pass em numpy. Sem ONNX, sem TorchScript, sem dependências de runtime além do numpy.
Defesa em Duas Camadas
- Motor de sinais:
.filter()descarta ordens com P(win) < limiar - Orquestrador de trades: gate defensivo rejeita qualquer sinal que passe
Cinto e suspensórios. Esse padrão de arquitetura — defesa em profundidade para execução de trades — permanece sólido mesmo após removermos o componente NN.
A Descoberta das Barras Fantasma
Essa foi a descoberta real.
Durante o deploy, trocamos a fonte de dados de uma API de terceiros para o copy_rates_from_pos() nativo do MT5. Mesmo símbolo, mesmo timeframe, mesma contagem de barras. Resultados diferentes.
A API retornava barras até sábado — dados sintéticos de fim de semana. Essas barras fantasma consumiam slots na nossa janela de 500 barras, empurrando dias de negociação reais para fora:
| Fonte | 500 barras cobrem | Última barra |
|---|---|---|
| API de terceiros | 11 Fev → 21 Fev (Sáb) | Sábado 17:00 ⚠️ |
| MT5 direto | 6 Fev → 20 Fev (Sex) | Sexta 23:30 ✅ |
MT5 dá 5 dias reais de negociação a mais de histórico. Dois sinais pendentes que existiam sob a API desapareceram sob o MT5 — corretamente identificados como já invalidados por barras que a janela truncada da API não conseguia ver.
Seu provedor de dados faz parte da sua estratégia. Mesma lógica, dados diferentes, trades diferentes. Cortamos o intermediário. Essa lição se aplica a toda estratégia sistemática, com NN ou não. Se você está usando uma API de dados de terceiros para alimentar sinais no MT5, compare a saída dela contra os dados nativos do MT5. Diferenças não são casos de borda — são divergência de execução.
Semana 1: Resultados Ao Vivo
Deploy em 17 de fevereiro de 2026 com €10.000 demo. O filtro NN não estava ativo para esses trades — são baseline puro:
| # | Data | Direção | Resultado | Pips | P&L Líquido |
|---|---|---|---|---|---|
| 1 | 18 Fev | LONG | ❌ SL | -10.0 | -€181 |
| 2 | 19 Fev | LONG | ✅ TP | +10.7 | +€229 |
| 3 | 20 Fev | LONG | ❌ SL | -8.5 | -€193 |
Semana 1: -€145.67 (-1.46%). 1 vitória, 2 derrotas. Três trades é ruído, não sinal.
O Epílogo: Nós Overfittamos
A última linha do post perguntava: “o edge do filtro persiste ao vivo, ou overfittamos 302 trades?”
Nós overfittamos 302 trades.
Por volta de 25 de fevereiro de 2026, o filtro NN foi removido do VPS ao vivo. A razão era simples: 302 amostras de treinamento não são suficientes para uma rede neural aprender padrões generalizáveis, mesmo uma de 593 parâmetros. Os padrões condicionais — dominância de segunda-feira, agrupamento em abertura de sessão — são features reais do price action EURUSD 30 minutos. Mas uma rede treinada em 302 exemplos desses padrões aprende os 302 trades específicos, não a estrutura subjacente.
A estratégia IPDA CE crua, sem nenhum filtro de rede neural, continuou operando. No início de março de 2026, a conta estava em €9.540,23, recuperando de um drawdown máximo de -6.14% para -4.6%. O edge vive na física de gap-fill e nas camadas de deflação que aplicamos antes de qualquer ML tocar nela. A NN era ornamentação.
GBPUSD — o “segundo par” que planejávamos deployar — nunca foi ao vivo. A estratégia é específica por ativo. Transfer learning entre pares forex produziu acurácia abaixo de moeda, e o modelo GBPUSD independente sofreu o mesmo problema de amostra pequena.
O que sobreviveu:
- A estratégia baseline. Cinco rodadas de deflação, validada em tick, ajustada por spread. Ainda operando, ainda lucrativa.
- A engenharia de deploy. Exportação PyTorch-para-numpy, arquitetura de defesa em duas camadas, gestão de recursos do VPS. Esses padrões funcionam independente de qual modelo você está rodando.
- A descoberta das barras fantasma. Divergência de provedor de dados é um risco real e pouco discutido em trading sistemático.
- A pergunta certa. “Nós overfittamos?” era a coisa certa a se perguntar. O erro foi não esperar dados out-of-sample suficientes antes de publicar os resultados in-sample como se fossem conclusões.
O que morreu:
- O filtro NN. 302 amostras, 593 parâmetros, ensemble de 10 seeds — nada disso foi suficiente. O backtest parecia limpo porque o modelo aprendeu o conjunto de treinamento, não o mercado.
- Ambições cross-pair. GBPUSD nunca foi deployado. O edge, se existe lá, precisa de seu próprio pipeline de validação — não um port do EURUSD.
A lição é velha mas aparentemente precisa ser reaprendida: se seu conjunto de treinamento cabe numa planilha, você não precisa de uma rede neural. Regras fixas — operar segundas, pular meio de sessão — teriam capturado os mesmos padrões condicionais sem o risco de overfitting. Nós recorremos a ML porque parecia sofisticado. O mercado não liga para sofisticação.
Próximos Passos
- Estratégia crua continua — IPDA CE no EURUSD 30m, sem filtro NN, sem enfeites
- Atualizações de equity semanais — performance real, sem cherry-picking. A conta está no vermelho mas recuperando.
- Regras fixas acima de modelos suaves — se padrões condicionais persistirem, filtros simples de dia/hora com dados forward suficientes, não redes neurais treinadas em 302 trades
Este post faz parte de uma série contínua documentando trading sistemático ao vivo com resultados honestos. Anterior: Começando Pelo Fim: Desafios de Prop Firm como Otimização de Variância.