Mercados São Linguagens, Não Física
Por que tratar mercados como linguagem produz modelos melhores que física. O framework por trás da nossa abordagem de trading com IA.
A Metáfora Errada
Por 50 anos, finanças quantitativas emprestou suas metáforas da física. Movimento browniano. Equações diferenciais estocásticas. Teoria de campo médio. A equação de Black-Scholes é literalmente a equação do calor com condições de contorno diferentes.
Essa metáfora foi extraordinariamente produtiva. Nos deu precificação de opções, gestão de risco, teoria de portfólio. Mas como framework para previsão, é fundamentalmente limitada — porque mercados não são sistemas físicos.
Sistemas físicos não leem jornal. Partículas não entram em pânico. A gravidade não muda de ideia porque o presidente do Fed usou uma palavra ligeiramente diferente numa coletiva.
Mercados são feitos de humanos que produzem linguagem, acreditam em narrativas e seguem manadas. E o melhor framework para modelá-los pode não ser física. Pode ser linguística.
A Pista da Renaissance
O fundo quantitativo mais bem-sucedido da história — o Medallion Fund da Renaissance Technologies — foi construído por matemáticos, mas não matemáticos de finanças. Jim Simons contratou criptógrafos, pesquisadores de reconhecimento de fala e linguistas computacionais. Robert Mercer veio da equipe de reconhecimento de fala da IBM. Peter Brown era pesquisador de tradução automática.
Isso não foi acidente. Simons buscou explicitamente pessoas que entendiam reconhecimento de padrões em dados sequenciais — que é exatamente o que processamento de linguagem natural é.
O registro público sugere que a Renaissance trata dados de mercado como uma espécie de linguagem: uma sequência de símbolos (movimentos de preço, padrões de volume, fluxo de ordens) que contém regularidades estatísticas análogas à gramática e sintaxe. Você não precisa entender por que uma palavra segue outra para prevê-la; precisa entender a estrutura estatística da sequência.
Mercados como Sequências de Tokens
Considere a analogia com mais precisão:
| Linguagem | Mercados |
|---|---|
| Palavras/tokens | Barras de preço, volume, eventos de fluxo de ordens |
| Gramática | Regras de microestrutura de mercado |
| Frases | Sessões de trading |
| Contexto | Regime, ambiente macro |
| Semântica | Valor fundamental |
| Pragmática | Intenção do trader, posicionamento |
| Registro/estilo | Regime de volatilidade |
Em NLP, um modelo de linguagem não precisa “entender” significado para gerar texto coerente. GPT não sabe o que é um gato, mas pode usar a palavra corretamente em contexto porque aprendeu as regularidades estatísticas de como “gato” se relaciona com outras palavras.
Da mesma forma, um modelo de mercado não precisa entender por que preços se movem. Precisa aprender as regularidades estatísticas de como eles se movem — a gramática da ação de preço.
import numpy as np
import pandas as pd
def tokenize_price_action(
df: pd.DataFrame,
n_price_bins: int = 20,
n_volume_bins: int = 5,
n_volatility_bins: int = 5,
) -> pd.Series:
"""
Convert OHLCV data into a sequence of discrete tokens,
analogous to tokenizing text for NLP.
Each bar becomes a token encoding: direction, magnitude,
volume regime, and volatility regime.
"""
df = df.copy()
# Price change as percentage of ATR (normalized magnitude)
tr = pd.concat([
df['high'] - df['low'],
(df['high'] - df['close'].shift(1)).abs(),
(df['low'] - df['close'].shift(1)).abs()
], axis=1).max(axis=1)
atr = tr.rolling(14).mean()
change = df['close'] - df['open']
normalized_change = change / atr
# Discretize price change
price_token = pd.qcut(normalized_change, n_price_bins, labels=False, duplicates='drop')
# Discretize volume (relative to average)
rel_volume = df['volume'] / df['volume'].rolling(50).mean()
vol_token = pd.qcut(rel_volume, n_volume_bins, labels=False, duplicates='drop')
# Discretize volatility regime
vol_regime = atr / atr.rolling(100).mean()
regime_token = pd.qcut(vol_regime, n_volatility_bins, labels=False, duplicates='drop')
# Composite token: "P{price}_V{volume}_R{regime}"
tokens = (
'P' + price_token.astype(str) +
'V' + vol_token.astype(str) +
'R' + regime_token.astype(str)
)
return tokensModelos N-gram: O Modelo de Linguagem Mais Simples para Mercados
Antes do deep learning, NLP dependia de modelos n-gram: prever a próxima palavra com base nas n-1 palavras anteriores. Podemos aplicar a mesma abordagem a tokens de mercado:
from collections import Counter, defaultdict
class MarketNgramModel:
"""
An n-gram language model for market token sequences.
Predicts the next market state based on the previous n-1 states.
"""
def __init__(self, n: int = 5):
self.n = n
self.ngram_counts = defaultdict(Counter)
self.context_counts = defaultdict(int)
def train(self, token_sequence: list[str]):
"""Train on a sequence of market tokens."""
for i in range(len(token_sequence) - self.n):
context = tuple(token_sequence[i:i + self.n - 1])
next_token = token_sequence[i + self.n - 1]
self.ngram_counts[context][next_token] += 1
self.context_counts[context] += 1
def predict_distribution(self, context: tuple) -> dict:
"""
Given the last n-1 tokens, predict the probability distribution
of the next token.
"""
if context not in self.ngram_counts:
return {}
total = self.context_counts[context]
return {
token: count / total
for token, count in self.ngram_counts[context].items()
}
def directional_bias(self, context: tuple, neutral_token_prefix: str = 'P10') -> float:
"""
Compute directional bias: probability of bullish vs bearish next token.
Tokens with price component > neutral are bullish, < neutral are bearish.
"""
dist = self.predict_distribution(context)
if not dist:
return 0.0
bullish_prob = sum(p for t, p in dist.items() if int(t.split('V')[0][1:]) > 10)
bearish_prob = sum(p for t, p in dist.items() if int(t.split('V')[0][1:]) < 10)
return bullish_prob - bearish_prob
def perplexity(self, token_sequence: list[str]) -> float:
"""
Compute perplexity — how 'surprised' the model is by the sequence.
High perplexity = unusual market behavior = potential regime change.
"""
log_probs = []
for i in range(self.n - 1, len(token_sequence)):
context = tuple(token_sequence[i - self.n + 1:i])
token = token_sequence[i]
dist = self.predict_distribution(context)
if token in dist and dist[token] > 0:
log_probs.append(np.log2(dist[token]))
else:
log_probs.append(-10) # smoothing for unseen tokens
return 2 ** (-np.mean(log_probs)) if log_probs else float('inf')Perplexidade como Detector de Mudança de Regime
A saída mais interessante do modelo de linguagem não é a previsão — é a perplexidade. Em NLP, perplexidade mede o quanto o modelo se surpreende com um texto. Alta perplexidade significa que o texto não segue os padrões que o modelo aprendeu.
Aplicado a mercados: alta perplexidade significa que o mercado está se comportando diferente de tudo que o modelo já viu. Isso é um indicador de mudança de regime — e é completamente agnóstico ao modelo. Você não precisa especificar que tipo de mudança de regime está procurando. O pico de perplexidade diz que algo mudou.
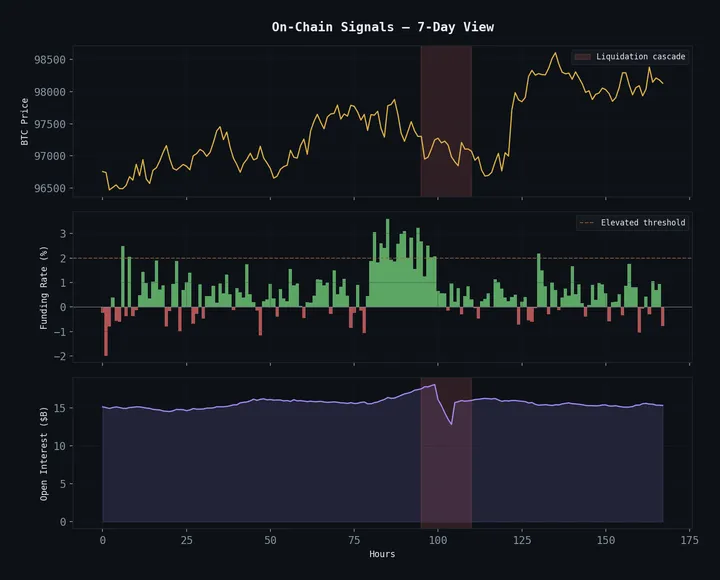
Rastreamos perplexidade rolante e descobrimos que ela dispara 4-12 barras antes de grandes eventos de volatilidade com uma consistência que rivaliza com nosso sinal de colapso de entropia. Os dois sinais são relacionados mas não idênticos — entropia mede o conteúdo informacional dos retornos diretamente, enquanto perplexidade mede quão inesperada a sequência de estados de mercado é.
Por Que LLMs São Modelos Naturais de Mercado
Este framework explica por que LLMs podem ser eficazes em análise de mercado (uma ideia que estamos testando com nosso agente de trading LLM):
-
Janelas de contexto. LLMs processam sequências com atenção a dependências de longo alcance. Mercados têm exatamente essa estrutura — o significado da barra atual depende do que aconteceu 50, 100 ou 500 barras atrás.
-
Raciocínio multi-modal. GPT-4 e Claude podem processar texto, números e dados estruturados simultaneamente. Análise de mercado exige sintetizar dados de preço, notícias, fundamentos e dados de posicionamento.
-
Aprendizado few-shot. LLMs podem se adaptar a novos padrões a partir de poucos exemplos. Mercados constantemente geram novos padrões que não apareceram em dados históricos.
-
Quantificação de incerteza. LLMs naturalmente produzem distribuições de probabilidade sobre os próximos tokens. Previsão de mercado é inerentemente probabilística — você quer P(alta) vs P(baixa), não uma previsão pontual.
Os Limites da Metáfora
A analogia com linguagem não é perfeita. Três diferenças importantes:
Não-estacionariedade. Linguagem natural é aproximadamente estacionária — a gramática do português não muda de mês a mês. A “gramática” do mercado muda com regimes macro, mudanças regulatórias e rotatividade de participantes. Modelos de linguagem treinados em dados de 2020 podem não generalizar para 2025.
Dinâmica adversarial. Quando participantes suficientes aprendem os mesmos padrões, esses padrões podem ser explorados ou desaparecer. Linguagem não tem falantes adversariais tentando fazer você prever errado. Mercados têm.
Reflexividade. Em linguagem, sua previsão da próxima palavra não muda qual será a próxima palavra. Em mercados, seu trade é parte do processo de formação de preço. O observador afeta o observado. (George Soros construiu uma filosofia inteira em torno disso.)
O Que Isso Significa para Nossa Pesquisa
O framework de linguagem molda nossas prioridades de pesquisa na Curupira:
- Preferimos reconhecimento estatístico de padrões a modelos causais. Não precisamos saber por que um padrão existe, apenas que é estatisticamente robusto.
- Usamos modelos de sequência (n-grams, mecanismos de atenção) ao invés de indicadores pontuais. A ordem dos eventos de mercado importa.
- Monitoramos perplexidade do modelo como sinal de primeira classe. Quando o mercado para de “fazer sentido” para nossos modelos, isso é informação.
- Implantamos LLMs para raciocínio contextual sobre sinais quantitativos, não como preditores diretos. O LLM é o intérprete, não o sensor.
Mercados não são física. Não são random walks perfeitamente eficientes. Não são sistemas determinísticos esperando para serem resolvidos. São sequências bagunçadas, evolutivas, reflexivas, guiadas por narrativa, produzidas por agentes imperfeitos.
São linguagens. E estamos construindo as ferramentas para lê-las.
Estamos testando este framework com um Agente de Trading LLM na Hyperliquid. Para o trabalho de sinais estatísticos, veja Colapso de Entropia ou Expoentes de Hurst.